Forums > Encoding > Hardsub OCR Guide
#1665904
by johnnydeep


 (Torrent Queen)
(OCD about OCR)
[ Jul 19 2019, 20:53 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Jul 19 2019, 20:53 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Jul 19 2019, 20:53 ] - [Quote]
[Report Post]
↑
Here's a lil guide I decided to create on how to extract hardcoded subtitles with relatively few manual fixes, which mostly depends on the picture quality, but still it's very effective. Until now, I used AVISubDetector to detect subtitles and enter the text manually, but that's so 2006.
The guide is based on a couple of other guides I've had a chance to study and try out. I'm not claiming the settings described in either of the guides below to be the best out there, but I personally saw great results that I'm really happy with.
You'll need:
1. Open your video in VideoSubFinder. Set the working area by moving the upper edge of the Video Box. Hit 'Run Search' for the program to scan the video and save the screenshots of the frames containing subtitles. The image filenames will contain the timecode and duration info, which will be used by the program later.
2. Go to the VideoSubFinder's RGBImages subfolder, skim through the files and delete the ones that do not contain subtitles.
3. Go back to VideoSubFinder's OCR tab and hit 'Create Cleared TXT Images', which will launch the process of cleaning up the images in the RGBImages folder.
4. Once the process is over, import the collection of generated images from the TXTImages folder to FineReader to be OCR'd (see the FR guide below if you are new to the program).
5. Save the OCR result in .txt format in the VideoSubFinder's TXTResults subfolder.
.txt doesn't preserve formatting, but we got no choice really, VideoSubFinder only works with .txt.
6. Launch VideoSubFinder, go to the OCR tab and hit 'Create Sub From TXT Results' to merge the saved .txt files into a single .srt file.
7. Open the .srt file in Notepad++, select 'Encode in ANSI' in Encoding menu, replace
8. Watch the hardsubbed version with external soft subs to detect any errors & OCR mishaps, retrieve formatting and make sure nothing is missing.**
9. [if you want to sync the subs to other source] Change the framerate of the subs in SubtitleEdit to match the other video's framerate, if needed.
9.1. Import the video in SubtitleEdit, enable the Waveform and Video options on the main panel, open the subtitles.
9.2. Adjust the timecodes using the waveform. Save.
*The BOM-characters are added by FineReader when saving in UTF-8, and it seems like there's no way around this little snag. If you don't get rid of them, they'll get in the way of automated formatting fixes, say, in SubtitleEdit. Also, these crappy characters may look differently when you open the subtitle in Notepad++. Just look for a bunch of weird characters at the beginning of all lines and replace them with blank.
**I do this in PotPlayer, which is pretty handy when it comes to subtitle adjustment, e.g. you can manually set the subtitle position on the screen to make the comparison with the hardsub as comfortable as possible.
Here's a lil guide to setting up and using FineReader 15.
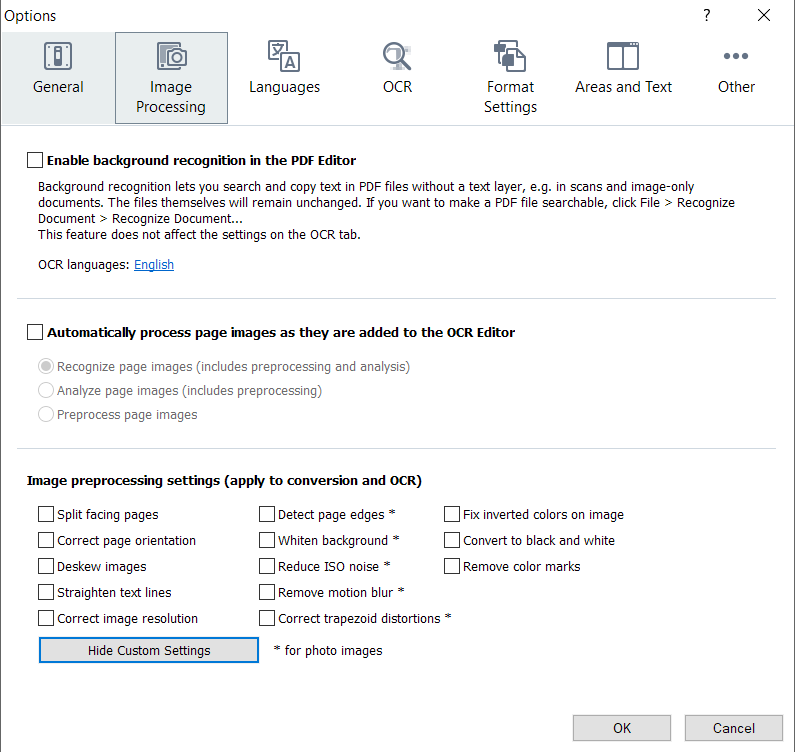
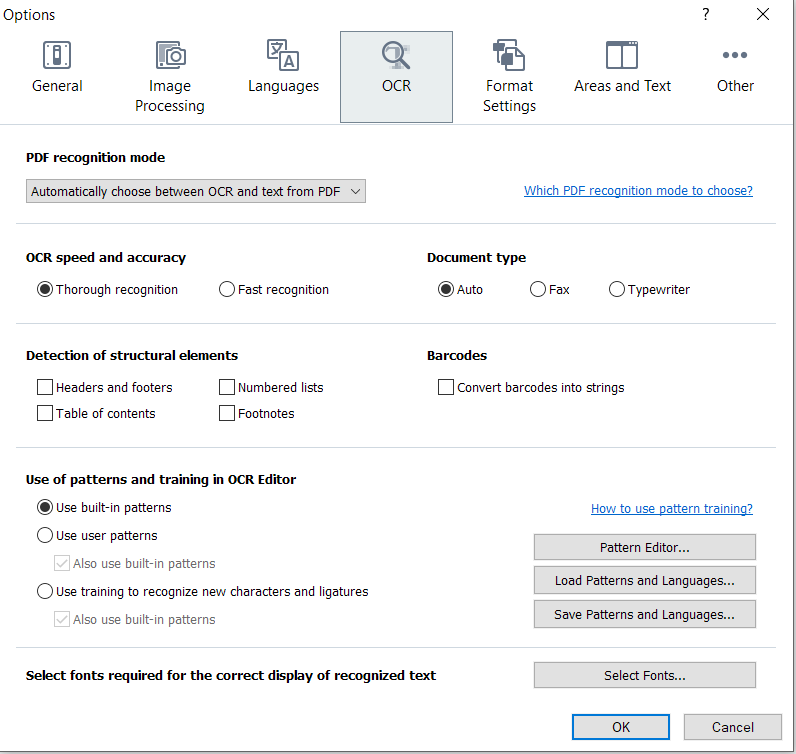
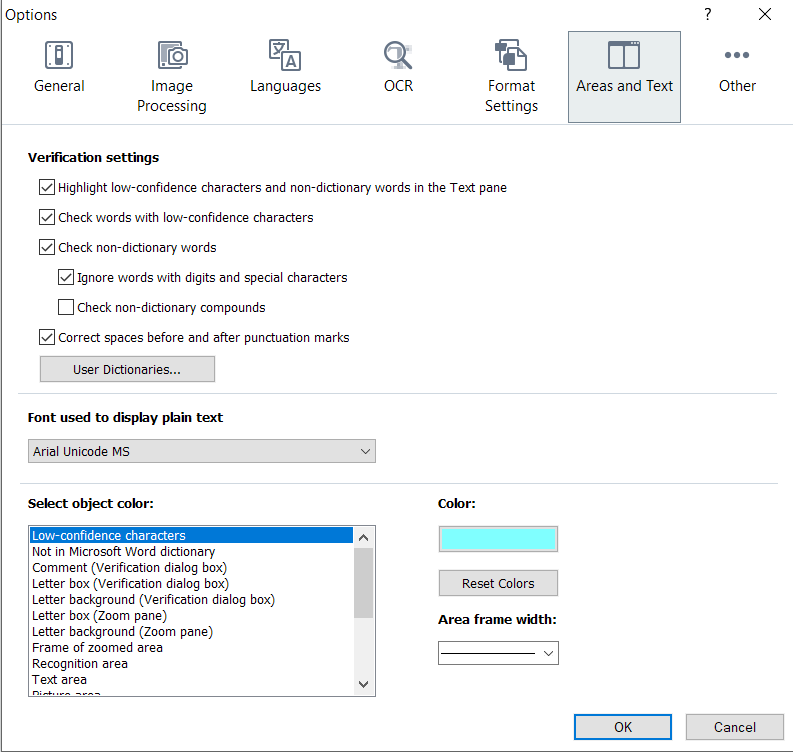
1. Launch FineReaderOCR.exe, go to Tools -> Options, do this:
Spoiler: Show
2. Add images from the VideoSubFinder's TXTImages folder to FR.
3. Select text language or several languages (depending on the subtitle language) on the main panel, right next to 'Read' button.
4. Find a bigger image, select its whole area (there's just text in it, so we're safe), go to Area menu, click on 'Save Area Template' and save it! Then go back to Area menu, hit on 'Load Area Template', select the file you just saved, select 'Apply to all pages' and hit 'Open'.
You can use this template for your future projects since FineReader's automated area detection tends to mess up and leave parts of text outside the working area. You may need to use a different area size template depending on the images you will be working with in the future.
5. Hit 'Recognize'.
6. Save the result as .txt in the TXTResults subfolder in VideoSubFinder's folder. When saving, make sure you select 'Create a separate file for each source file' at the bottom of the 'Save document as' window.
7. See Step 6 of the guide above.
Last modified on: July 30, 2020
Feel free to share the guide if you think it's worth sharing.
Thx to @Elheym, @DonLK, @HyerrDoktyer, @SlappyTime for all sorts of useful tips and info about subtitles and stuff.
The guide is based on a couple of other guides I've had a chance to study and try out. I'm not claiming the settings described in either of the guides below to be the best out there, but I personally saw great results that I'm really happy with.
You'll need:
- VideoSubFinder
- FineReader 15
- PotPlayer (optional)
- Subtitle Edit (optional)
1. Open your video in VideoSubFinder. Set the working area by moving the upper edge of the Video Box. Hit 'Run Search' for the program to scan the video and save the screenshots of the frames containing subtitles. The image filenames will contain the timecode and duration info, which will be used by the program later.
2. Go to the VideoSubFinder's RGBImages subfolder, skim through the files and delete the ones that do not contain subtitles.
3. Go back to VideoSubFinder's OCR tab and hit 'Create Cleared TXT Images', which will launch the process of cleaning up the images in the RGBImages folder.
4. Once the process is over, import the collection of generated images from the TXTImages folder to FineReader to be OCR'd (see the FR guide below if you are new to the program).
5. Save the OCR result in .txt format in the VideoSubFinder's TXTResults subfolder.
.txt doesn't preserve formatting, but we got no choice really, VideoSubFinder only works with .txt.
6. Launch VideoSubFinder, go to the OCR tab and hit 'Create Sub From TXT Results' to merge the saved .txt files into a single .srt file.
7. Open the .srt file in Notepad++, select 'Encode in ANSI' in Encoding menu, replace
 with blank, select 'Encode in UTF-8' in Encoding menu, save.* 8. Watch the hardsubbed version with external soft subs to detect any errors & OCR mishaps, retrieve formatting and make sure nothing is missing.**
9. [if you want to sync the subs to other source] Change the framerate of the subs in SubtitleEdit to match the other video's framerate, if needed.
9.1. Import the video in SubtitleEdit, enable the Waveform and Video options on the main panel, open the subtitles.
9.2. Adjust the timecodes using the waveform. Save.
*The BOM-characters are added by FineReader when saving in UTF-8, and it seems like there's no way around this little snag. If you don't get rid of them, they'll get in the way of automated formatting fixes, say, in SubtitleEdit. Also, these crappy characters may look differently when you open the subtitle in Notepad++. Just look for a bunch of weird characters at the beginning of all lines and replace them with blank.
**I do this in PotPlayer, which is pretty handy when it comes to subtitle adjustment, e.g. you can manually set the subtitle position on the screen to make the comparison with the hardsub as comfortable as possible.
Here's a lil guide to setting up and using FineReader 15.
1. Launch FineReaderOCR.exe, go to Tools -> Options, do this:
Spoiler: Show
2. Add images from the VideoSubFinder's TXTImages folder to FR.
3. Select text language or several languages (depending on the subtitle language) on the main panel, right next to 'Read' button.
4. Find a bigger image, select its whole area (there's just text in it, so we're safe), go to Area menu, click on 'Save Area Template' and save it! Then go back to Area menu, hit on 'Load Area Template', select the file you just saved, select 'Apply to all pages' and hit 'Open'.
You can use this template for your future projects since FineReader's automated area detection tends to mess up and leave parts of text outside the working area. You may need to use a different area size template depending on the images you will be working with in the future.
5. Hit 'Recognize'.
6. Save the result as .txt in the TXTResults subfolder in VideoSubFinder's folder. When saving, make sure you select 'Create a separate file for each source file' at the bottom of the 'Save document as' window.
7. See Step 6 of the guide above.
Last modified on: July 30, 2020
Feel free to share the guide if you think it's worth sharing.
Thx to @Elheym, @DonLK, @HyerrDoktyer, @SlappyTime for all sorts of useful tips and info about subtitles and stuff.
Last edited by
johnnydeep [ Jul 30 2020, 04:07 ]
#1665921
by DonLK (Torrent Master)
(مفتي التلفزيون)
[ Jul 19 2019, 21:40 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(مفتي التلفزيون)
[ Jul 19 2019, 21:40 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(مفتي التلفزيون)
[ Jul 19 2019, 21:40 ] - [Quote]
[Report Post]
↑

This is a great guide, thanks for sharing @johnnydeep
your secret plan to demote me to power user is going nicely
your secret plan to demote me to power user is going nicely
#1665997
by zoocey (Torrent King)
(Meow)
[ Jul 20 2019, 05:46 ] - [Quote]
[Report Post]
↑
(Torrent King)
(Meow)
[ Jul 20 2019, 05:46 ] - [Quote]
[Report Post]
↑

I tried AVISubDetector and SubRip years ago to try to OCR SBS Australia videos (they have a large collection of foreign films with hard-coded subs and abysmal video quality) with very limited success. I'll have to give this a try, thanks.
#1666009
by DonLK (Torrent Master)
(مفتي التلفزيون)
[ Jul 20 2019, 07:31 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(مفتي التلفزيون)
[ Jul 20 2019, 07:31 ] - [Quote]
[Report Post]
↑
zoocey wrote: 
Funnily enough, this is exactly what we're using it for lol
I tried AVISubDetector and SubRip years ago to try to OCR SBS Australia videos (they have a large collection of foreign films with hard-coded subs and abysmal video quality) with very limited success. I'll have to give this a try, thanks.
Funnily enough, this is exactly what we're using it for lol
#1666010
by HyerrDoktyer

 (Torrent Master)
[ Jul 20 2019, 07:37 ] - [Quote]
[Report Post]
↑
(Torrent Master)
[ Jul 20 2019, 07:37 ] - [Quote]
[Report Post]
↑
(Torrent Master)
[ Jul 20 2019, 07:37 ] - [Quote]
[Report Post]
↑
Nice work putting this together, I'm sure this will be a valuable resource to many.
#1666016
by jumpcat (User)
[ Jul 20 2019, 08:30 ] - [Quote]
[Report Post]
↑
(User)
[ Jul 20 2019, 08:30 ] - [Quote]
[Report Post]
↑
(User)
[ Jul 20 2019, 08:30 ] - [Quote]
[Report Post]
↑

Thanks.
#1667263
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Jul 24 2019, 18:17 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Jul 24 2019, 18:17 ] - [Quote]
[Report Post]
↑
UPD JUL 24, 2019:
Replaced the third screenshot under the FineReader settings spoiler. You gotta select Plain Text instead of Formatted Text to prevent FineReader from adding redundant spaces at the beginning of lines.
Replaced the third screenshot under the FineReader settings spoiler. You gotta select Plain Text instead of Formatted Text to prevent FineReader from adding redundant spaces at the beginning of lines.
Last edited by
johnnydeep [ Jul 27 2019, 05:38 ]
#1667269
by durfu
 (Torrent King)
[ Jul 24 2019, 18:48 ] - [Quote]
[Report Post]
↑
(Torrent King)
[ Jul 24 2019, 18:48 ] - [Quote]
[Report Post]
↑
(Torrent King)
[ Jul 24 2019, 18:48 ] - [Quote]
[Report Post]
↑

This works as well as it looks.
#1668352
by cybernaut (Torrent Master)
[ Jul 28 2019, 08:48 ] - [Quote]
[Report Post]
↑
(Torrent Master)
[ Jul 28 2019, 08:48 ] - [Quote]
[Report Post]
↑

That's a well detailed guide brother, I didn't expect nothing less from you! Thank you for this and I'm sure the community appreciate your work.
Cheers to you and to everyone who helped you!
Cheers to you and to everyone who helped you!
#1668428
by albatros44 (Elite)
[ Jul 28 2019, 18:15 ] - [Quote]
[Report Post]
↑
(Elite)
[ Jul 28 2019, 18:15 ] - [Quote]
[Report Post]
↑
(Elite)
[ Jul 28 2019, 18:15 ] - [Quote]
[Report Post]
↑

Thanks. good work
#1673255
by loli (Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 14 2019, 09:34 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 14 2019, 09:34 ] - [Quote]
[Report Post]
↑

Help: there is something wrong:
The single OCRed text is right, but when creating from TXT Results, the text shows "#unrecognized text#".
E.G:
0_02_05_874__0_02_06_873_00634.txt:
这是兰汐(Right Chinese)
sub.srt:
1
00:02:05,874 --> 00:02:06,873
#unrecognized text#
Is there any solution?
The single OCRed text is right, but when creating from TXT Results, the text shows "#unrecognized text#".
E.G:
0_02_05_874__0_02_06_873_00634.txt:
这是兰汐(Right Chinese)
sub.srt:
1
00:02:05,874 --> 00:02:06,873
#unrecognized text#
Is there any solution?
#1673294
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 14 2019, 14:47 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 14 2019, 14:47 ] - [Quote]
[Report Post]
↑
@loli, the txt was saved in UTF8?
#1673486
by loli (Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 15 2019, 05:41 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 15 2019, 05:41 ] - [Quote]
[Report Post]
↑
#1673555
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 15 2019, 14:49 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 15 2019, 14:49 ] - [Quote]
[Report Post]
↑
@loli, I contacted the VideoSubFinder developer, he tried to OCR Chinese subs, save the .txt in UTF8 (in Windows 10) and creating the .srt file with VSF. It worked.
Could you send a couple of your .txt files?
Could you send a couple of your .txt files?
#1673700
by loli (Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 16 2019, 03:29 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 16 2019, 03:29 ] - [Quote]
[Report Post]
↑
johnnydeep wrote:
Many thanks for your time and support. Here is the txt files in google drive:
https://mega.nz/file/ikEDiCjb#FL5QUDjaLSL29MFQb31VULlK2ZoHLRRpOVKd2DK5SgQ
@loli, I contacted the VideoSubFinder developer, he tried to OCR Chinese subs, save the .txt in UTF8 (in Windows 10) and creating the .srt file with VSF. It worked.
Could you send a couple of your .txt files?
Many thanks for your time and support. Here is the txt files in google drive:
https://mega.nz/file/ikEDiCjb#FL5QUDjaLSL29MFQb31VULlK2ZoHLRRpOVKd2DK5SgQ
#1673704
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 16 2019, 04:15 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 16 2019, 04:15 ] - [Quote]
[Report Post]
↑
@loli, I just tried it myself and it worked fine. I'm using VideoSubFinder 4.00, Windows 10. Did you tweak any VSF settings? I didn't.
#1673729
by DonLK (Torrent Master)
(مفتي التلفزيون)
[ Aug 16 2019, 08:33 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(مفتي التلفزيون)
[ Aug 16 2019, 08:33 ] - [Quote]
[Report Post]
↑
didn't know 4.0 was out already, any noticeable improvements?
#1673738
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 16 2019, 10:41 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 16 2019, 10:41 ] - [Quote]
[Report Post]
↑
DonLK wrote:
didn't know 4.0 was out already, any noticeable improvements?Yeah, I think that image clearing feature works a bit better in v.4
#1674261
by loli (Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 18 2019, 08:10 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(Eating+Drinking+Playing=Happiness)
[ Aug 18 2019, 08:10 ] - [Quote]
[Report Post]
↑
johnnydeep wrote:
That is strange. I tried on another computer, and it didn't work, eitther.
The two computers' OS are both win7 64 bit. Maybe OS is the problem that lies in?
@loli, I just tried it myself and it worked fine. I'm using VideoSubFinder 4.00, Windows 10. Did you tweak any VSF settings? I didn't.
That is strange. I tried on another computer, and it didn't work, eitther.
The two computers' OS are both win7 64 bit. Maybe OS is the problem that lies in?
#1674518
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 19 2019, 06:59 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 19 2019, 06:59 ] - [Quote]
[Report Post]
↑
@loli, asked a friend who's using Win 7 64 bit to give it a try and it worked.
I don't see how you could get 'unrecognized text' in the final .srt if the original .txt does not have 'unrecognized text'. I think you mixed the folders/files or something.
'unrecognized text' is what you get when FineReader fails to OCR the image. Then you'll have a .txt with 'unrecognized text' and, eventually, an .srt with 'unrecognized text' in this particular line.
Make sure you clear the VideoSubFinder's folders (you can use the Clear Folders button) to avoid potential mess/confusion.
I don't see how you could get 'unrecognized text' in the final .srt if the original .txt does not have 'unrecognized text'. I think you mixed the folders/files or something.
'unrecognized text' is what you get when FineReader fails to OCR the image. Then you'll have a .txt with 'unrecognized text' and, eventually, an .srt with 'unrecognized text' in this particular line.
Make sure you clear the VideoSubFinder's folders (you can use the Clear Folders button) to avoid potential mess/confusion.
#1674723
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Aug 20 2019, 04:24 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Aug 20 2019, 04:24 ] - [Quote]
[Report Post]
↑
VideoSubFinder 4.30 is out.
Looks like the Create Cleared TXT Images feature has been improved further.
Looks like the Create Cleared TXT Images feature has been improved further.
Last edited by
johnnydeep [ Sep 28 2019, 03:57 ]
#1686114
by marshmellowv (Torrent Master)
(Peep)
[ Sep 27 2019, 23:09 ] - [Quote]
[Report Post]
↑
(Torrent Master)
(Peep)
[ Sep 27 2019, 23:09 ] - [Quote]
[Report Post]
↑

WOW. i humbly bow at your feet for this thread. 
i'm shocked at how well this worked!! got subs transcribed and perfectly synced up (tho japanese stuff tends to be easily syncable) in no time. did have to fix a bunch of lines as i was proofwatching, but that's nothing compared to manually timing and transcribing.
heres the film i transcribed using this method - Zentai [2013] - x264 / MKV / DVD / 720x404
hope for more to come! my 'stitch' folder (stuff to sync, transcribe, etc.) may finally get a lil slimmer
i'm shocked at how well this worked!! got subs transcribed and perfectly synced up (tho japanese stuff tends to be easily syncable) in no time. did have to fix a bunch of lines as i was proofwatching, but that's nothing compared to manually timing and transcribing.
heres the film i transcribed using this method - Zentai [2013] - x264 / MKV / DVD / 720x404
hope for more to come! my 'stitch' folder (stuff to sync, transcribe, etc.) may finally get a lil slimmer
#1686194
by johnnydeep (Torrent Queen)
(OCD about OCR)
[ Sep 28 2019, 03:59 ] - [Quote]
[Report Post]
↑
(Torrent Queen)
(OCD about OCR)
[ Sep 28 2019, 03:59 ] - [Quote]
[Report Post]
↑

#1695950
by MehrAzar (Torrent Master)
[ Oct 26 2019, 23:46 ] - [Quote]
[Report Post]
↑
(Torrent Master)
[ Oct 26 2019, 23:46 ] - [Quote]
[Report Post]
↑

Les.Rivieres.pourpres.AKA.The.Crimson.Rivers.S01.2018.720p.BluRay.x264-HANDJOB
Thanks man!
English subtitles' note:
Source: The.Crimson.Rivers.2018.S01.1080p.AMZN.WEB-DL.DDP2.0.H.264-iJP (Thanks man!)
The hardsubs of the AMZN release were completely OCRed
based on this step-by-step guidance: Hardsub OCR Guide
Credits and special thanks to the author.
Thanks man!
#1696601
by morgnCore (Power User)
[ Oct 28 2019, 19:47 ] - [Quote]
[Report Post]
↑
(Power User)
[ Oct 28 2019, 19:47 ] - [Quote]
[Report Post]
↑

@johnnydeep
first of all, great guide, thx a lot for this!
so my problem: i do everything the same, it works perfectly, but i only have one timecode in the first line. OCRed everything well (maybe a few mistakes, i will check it later), but i only have one timecode
1
00:00:00,000 --> 00:00:01,000
any ideas?
The image filenames will contain the timecode and duration info, which will be used by the program later.
first of all, great guide, thx a lot for this!
so my problem: i do everything the same, it works perfectly, but i only have one timecode in the first line. OCRed everything well (maybe a few mistakes, i will check it later), but i only have one timecode
1
00:00:00,000 --> 00:00:01,000
any ideas?